这个Anti-Cheat方法为了解决什么问题?
一般来说,一款网页\手机游戏纯靠客户端来解决反作弊(Anti-Cheat)几乎是不可能的。在这种情形下,页游\手游客户端(后文均称游戏客户端)可以利用一些手段来增加作弊\破解人员的成本,包括但不限于:代码加密,代码混淆,隐藏明文,内存混淆(加密)……
这个方法主要是避免\检测出类似CE工具对客户端内存进行恶劣修改达到关键数据变更的行为,属于上面提到的内存混淆(加密)类。
本文建立在所有源码未被对方知晓的情况下进行操作……
内存混淆(加密)通用做法
游戏客户端将原始数据保留二份,一份原始数据,一份加密数据。调用set()方法时,原始数据赋原始值,加密数据采用加密方法存储数据(比较基础的方法是数据异或);调用get()方法时,对加密数据与原始数据进行校验,通过校验结果是否一致来判定内存是否被修改。
我们以整形为例,大致的实现:
class IntShadow {
public:
int get() {
if (origi != shadow ^ salt) {
//这里处理内存被修改
}
return origi;
}
void set(int setInt) {
salt = rand();
origi = setInt;
shadow= setInt ^ salt;
}
private:
int origi;
int shadow;
int salt;
};
既然是造轮子,那么这个轮子的特点 – class BinarySep
1、使用简单
这个Anti-Cheat的方法使用方式类似于std::vector,例如:
BinarySep<int32_t>; a(1); BinarySep<int64_t>; b(12345); BinarySep<bool>; c(false);
2、通用
支持所有的连续内存的基础类型包括不限于int32_t,double,bool,std::string(char *),其中string实现是将内容转化成为char *处理,也可以使用std::vector<BinarySep<int32_t> >进行嵌套使用。堆里的内容也可以转化成为char *处理。
3、混淆\加密性较强
将内存分片化处理,按32\64位机器内存对齐方式进行结构体随机数填充,来增加修改者寻找规律的复杂度。细节如下图:
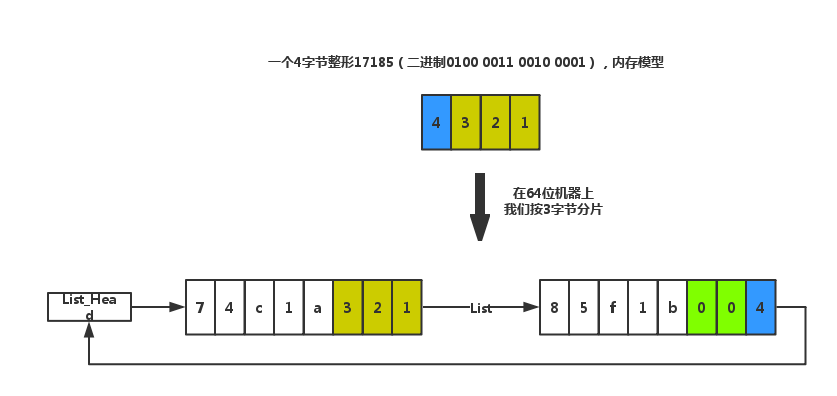
在List上,黄色\蓝色字节处为原始数据字节,其他字节均用随机字符填充。其中原始字节可以进行异或混淆或者Base64之类的方法混淆加密。
这里这样做的原因主要是struct unit_list结构体,在64位机器上若取3字节分片,那么sizeof(struct unit_list)==24,故我们将多余的5个字节当做padding填充随机字符。
需要注意的是,当分片大小取8时,padding[0]会导致部分编译器无法编译通过。
一些不足
占用空间大
初略计算一个占4字节的整形需要40字节的栈空间,48字节的堆空间(主要是链表)。由于链表使用的是linux内核的侵入式链表,它是双向的(这里优化点-可以改成单向,节约24字节的空间)。所以建议使用它对关键数据混淆\加密,而非所有数据。
一些类型使用需小心
比较典型是string类型,使用了堆空间进行存储,从储存到获取是一个string->char*->string的过程。对于结构体类型可以直接混淆存储或者序列化成char *存储(但是结构体里指向堆内容指针无法直接处理)。
未支持所有运算符
目前只重载了”=”运算符,对于”!=”、”==”、”>”…之类的运算符可以调用get()方法获得基本类型后比较,比如:
BinarySep<int32_t>; a(1);
BinarySep<int32_t>; b(2);
if (a.get() > b.get()) {
//...
} else if (a.get() < 0) {
//...
}
本文对Anti-Cheat中内存混淆(加密)的源码实现未投入实际项目上线运行。
源码戳这里 -> Anti-Cheat BinarySep
(全文结束)
转载文章请注明出处:漫漫路 - lanindex.com
我好笨,我还以为我看错了,原来亦或再异或就会回来原来的值