超时问题
Https请求超时一般指的是从Https请求发起计时,在规定时间内没有返回响应,造成请求超时。使用Golang语言为例,默认客户端没有设置超时时间,即请求一直等待返回,我们可以通过下面代码设置客户端的请求超时为5秒:
var client = &http.Client{
Timeout: time.Second * 5,
}
绝大多数情况下,超时请求会返回关键词为“context deadline exceeded (Client.Timeout exceeded while awaiting headers)”的错误信息,少数情况下也会因为超时导致的其他信息返回。
Golang语言也支持设置更细粒度的超时机制,例如在TCP链接建立阶段,在SSL握手阶段等等,主要是根据Https请求阶段来进行分解的。可以参考这边文章(The complete guide to Go net/http timeouts),文中讲解的比较透彻,借里面的一张图来说明更细粒度的请求超时拆解:
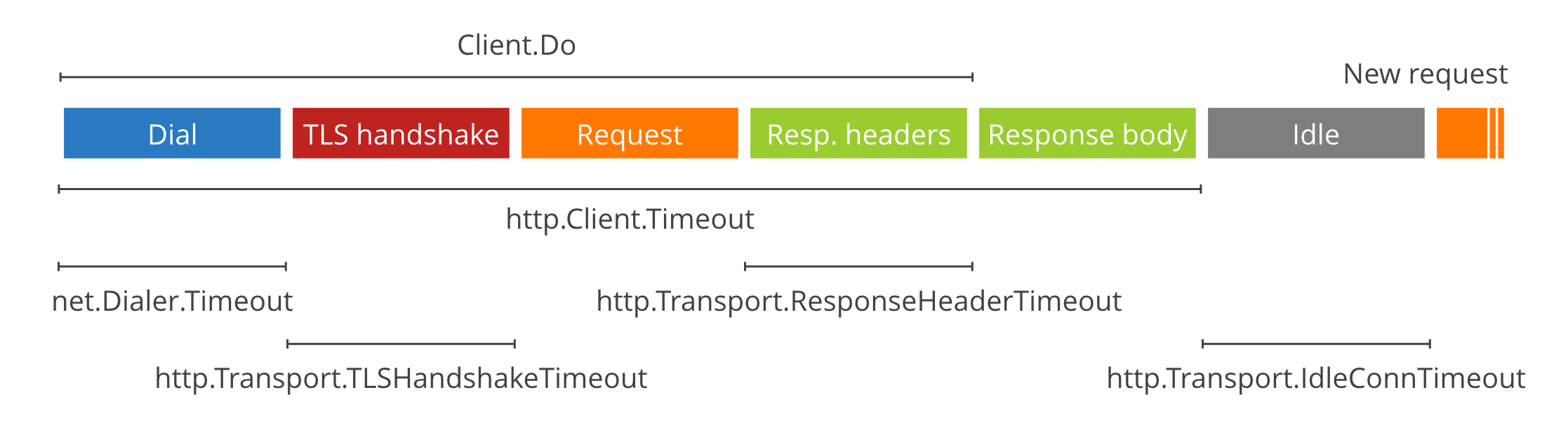
其中http.Client.Timeout就是文章开头代码所设置的超时时间,本文讨论的超时也是从这个点延伸出去的。其余的超时机制以及Trace它们方式会在下篇里做详细介绍。
问题发现
对于问题发现来说,其实不单单是Https请求返回的问题,一些内部错误,逻辑错误等也适用。所以说这块内容具有通用性。
线上运行的项目,无论是客户端还是服务器,都希望第一时间直接获取准确的错误信息,得到信息后及时进行问题排查,减少损失。
一般来说问题发现分为这几个步骤:
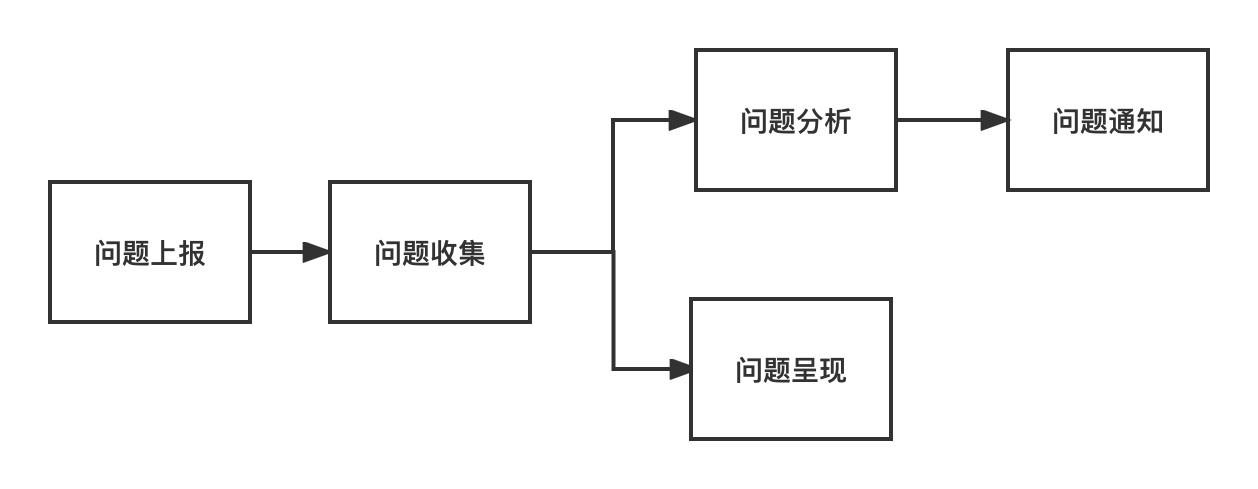
我们这里不关注问题上报、收集、呈现步骤实现的细节,业界的成熟方案比较多。总的来说如果业务体量较大,可能会在时效与成本之间权衡;业务体量较小采用何种方案其实就见仁见智了。
问题通知的方案更依赖公司办公沟通软件背景,时下流行的企业微信、飞书、钉钉均支持自定义消息的通知;紧急、重要的内容也可以直接通过手机短信或者电话通知。
其实对于问题通知来说,除了如何通知之外,更需要关注的是如何有效通知,类似于《狼来了》的故事在问题发现中也会时而发生。
有效通知更多依赖问题分析的实现,一般来说针对Https请求超时的问题分析可以按照三个维度来实现:
| 分析维度 | 分析口径 | 目的 | 说明 |
| 分钟级 | 1分钟 | 发现实时的问题 | 每分钟统计请求超时数量 |
| 小时级 | 1小时 | 发现近期的问题,观察服务时段稳定性 | 每小时统计请求超时数量 |
| 天级 | 1天 | 天维度的问题,观察服务劣化 | 每天统计请求超时数量 |
每个口径需要设置一个阈值,这个需要根据具体业务特点、对方承诺的接口服务质量以及链路是否公网内网来定,举个例子:分钟级的阈值可以设置成2或者0.02%,连续2分钟达到或超过阈值后进行通知;小时级的阈值60或者0.01%,达到或超过阈值后进行通知等等之类的告警通知规则。
问题通知到对应负责人后进入排查阶段。
问题排查
在进入问题排查之前,我们先看一下客户端请求的链路图(每个请求业务所处的环境不同,所以这只是一个大概的示意图,绘出一些更具普适性的关键节点):
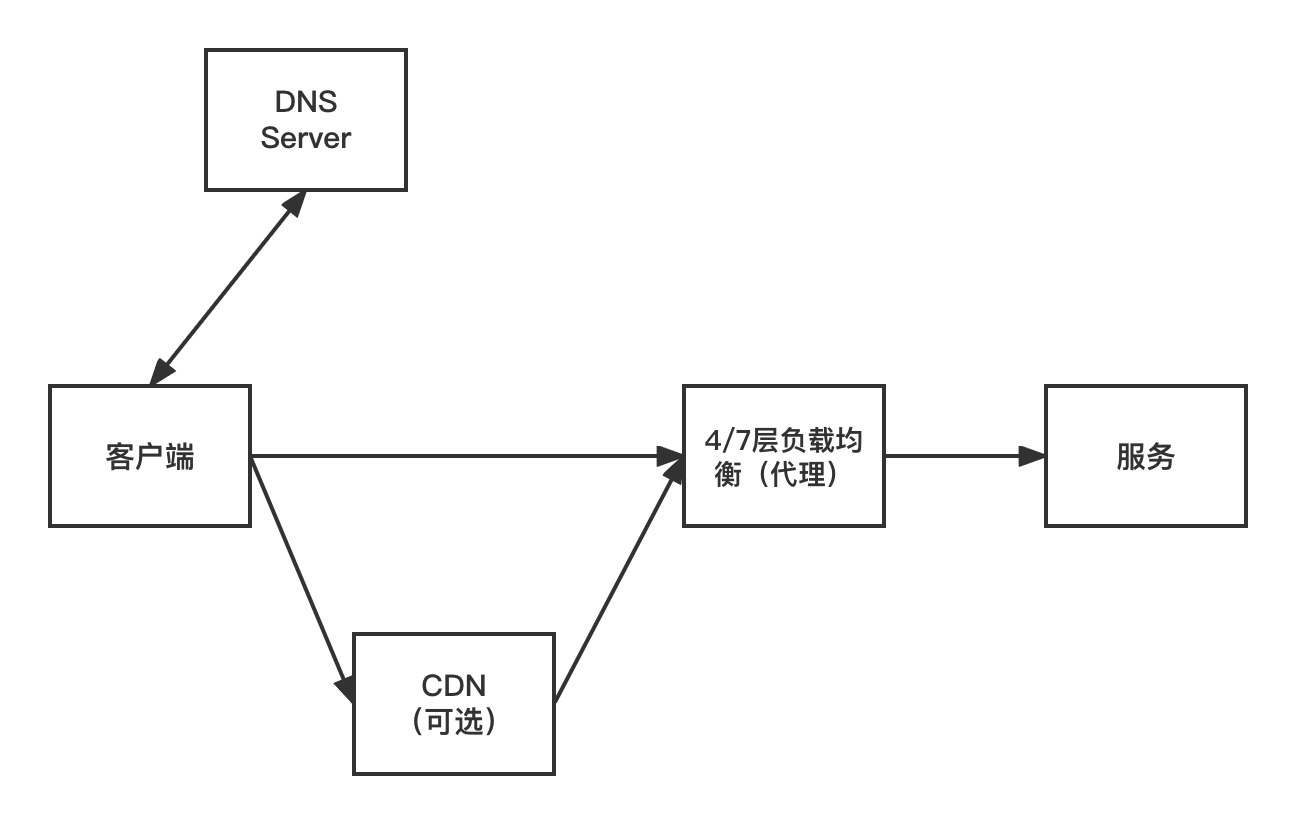
理论上来说链路里任何一个节点都可能导致请求超时,但是建议的思路是先自查,然后再从链路最下游(服务端)一级级向上查询。
问题排查还有一些比较通用注意事项:
- 各端所在机器时间戳可能存在不一致;
- 最好提前确定消息Trace方案。通常来说在CDN和4/7层代理不会对请求Body做解析,可能需要提前确定TraceID的传递方式,通常可以利用Header或者UrlParam;
- 做Trace机制的目的是为了更准确的归因与数据对齐;
客户端自查
先自查是一个良好的习惯,至少有一半的问题都可以通过自查归因。一般来说有以下点可以查看:
- 客户端所在进程、线程是否异常,可以通过日志、监控来观察;
- 程序所在机器CPU负载,网络出入流量是否有尖刺或者其他异常;
- 请求关键字段是否非法,对方采取了静默超时处理;
- 如果是突发所有请求超时,可以看看是否被机器或者网关防火墙阻挡(有人临时修改了策略);
- 通过文章开头的Https请求阶段的Trace日志进行初步诊断(下篇会详细介绍);
同时也可以进行横向比对:
- 程序所在机器其他客户端进程是否有异常,目的是初步诊断机器出口网络是否异常;
- 若客户端是多点的,另外一台机器上的同类客户端请求是否存在异常,目的是初步诊断对方服务是否异常;
服务端排查
第二步直接联系服务提供者进行排查,选取一些超时请求进行排查:
- 请求都未收到,直接进入4/7层代理排查;
- 请求均收到,服务端内部排查原因(耗时、数据下游依赖等),如果没有问题比对发送和接收到的时间戳;
- 请求部分收到,比对发送和接收到的时间戳,然后服务端内部排查原因;
如果传输耗时不在预期,均需要进入4/7层代理排查。
4/7层代理排查
一般来说Https服务会有一个4层公网链路的代理,后面再接一个7层的内部代理,这里将其简化统一了。因为其技术的成熟性,内部问题概率较小,所以问题排查更多聚焦代理上下游以及所处环境:
- 请求都未收到,若有使用CDN则直接进入CDN排查;
- 请求均收到,检查代理本身或者环境的异常,同时关注至服务端RT(Response Time)耗时,使用RT时间可以诊断出代理到服务端链路的传输耗时;
- 请求部分收到,比对发送和接收到的时间戳;
CDN排查
CDN一般对于Https请求来说是一个可选项,排查问题思路和代理有很多相似之处:
- 请求都未收到,客户端到CDN的链路问题或者客户端自身问题;
- 请求均收到,CDN内部排查,看看CDN回源耗时和RT耗时;
- 请求部分收到,大概率是客户端到CDN链路问题;
DNS排查
一般来说DNS出问题概率较小,我们主要关注的是DNS解析出来的地址,次要关注解析耗时。这里部分内容属于请求Trace的一部分,会在下篇做更详细的介绍。
写在末尾
最后总结几点:
- 超时问题是一个根据不同业务场景有着无限可能性的问题;
- 有一些通用的经验与方法论可以参考,但是对应到具体问题还是需要具体分析;
- 先自查,先自查,先自查;
(全文结束)
转载文章请注明出处:漫漫路 - lanindex.com
1 Comment
Add your comment