Twitter-Snowflake算法产生的背景相当简单,为了满足Twitter每秒上万条消息的请求,每条消息都必须分配一条唯一的id,这些id还需要一些大致的顺序(方便客户端排序),并且在分布式系统中不同机器产生的id必须不同。
Snowflake算法核心
把时间戳,工作机器id,序列号组合在一起。
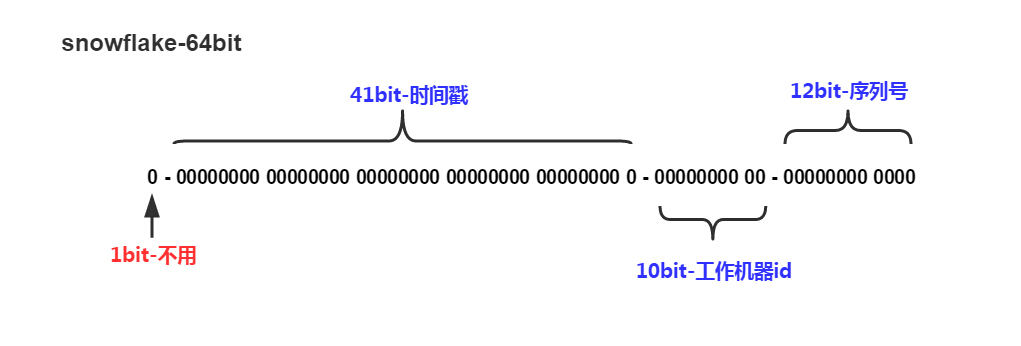
除了最高位bit标记为不可用以外,其余三组bit占位均可浮动,看具体的业务需求而定。默认情况下41bit的时间戳可以支持该算法使用到2082年,10bit的工作机器id可以支持1023台机器,序列号支持1毫秒产生4095个自增序列id。下文会具体分析。
Snowflake – 时间戳
这里时间戳的细度是毫秒级,具体代码如下,建议使用64位linux系统机器,因为有vdso,gettimeofday()在用户态就可以完成操作,减少了进入内核态的损耗。
uint64_t generateStamp()
{
timeval tv;
gettimeofday(&tv, 0);
return (uint64_t)tv.tv_sec * 1000 + (uint64_t)tv.tv_usec / 1000;
}
默认情况下有41个bit可以供使用,那么一共有T(1llu << 41)毫秒供你使用分配,年份 = T / (3600 * 24 * 365 * 1000) = 69.7年。如果你只给时间戳分配39个bit使用,那么根据同样的算法最后年份 = 17.4年。
Snowflake – 工作机器id
严格意义上来说这个bit段的使用可以是进程级,机器级的话你可以使用MAC地址来唯一标示工作机器,工作进程级可以使用IP+Path来区分工作进程。如果工作机器比较少,可以使用配置文件来设置这个id是一个不错的选择,如果机器过多配置文件的维护是一个灾难性的事情。
这里的解决方案是需要一个工作id分配的进程,可以使用自己编写一个简单进程来记录分配id,或者利用Mysql auto_increment机制也可以达到效果。
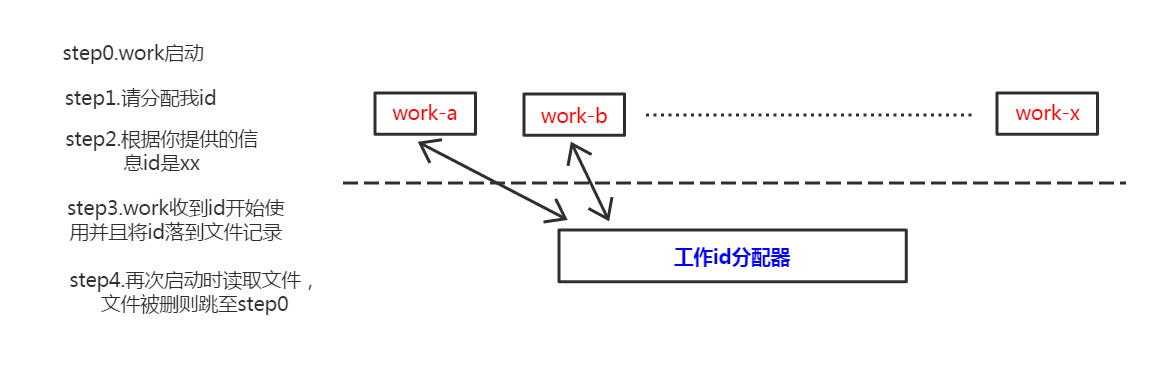
工作进程与工作id分配器只是在工作进程启动的时候交互一次,然后工作进程可以自行将分配的id数据落文件,下一次启动直接读取文件里的id使用。
PS:这个工作机器id的bit段也可以进一步拆分,比如用前5个bit标记进程id,后5个bit标记线程id之类:D
Snowflake – 序列号
序列号就是一系列的自增id(多线程建议使用atomic),为了处理在同一毫秒内需要给多条消息分配id,若同一毫秒把序列号用完了,则“等待至下一毫秒”。
uint64_t waitNextMs(uint64_t lastStamp)
{
uint64_t cur = 0;
do {
cur = generateStamp();
} while (cur <= lastStamp);
return cur;
}
总体来说,是一个很高效很方便的GUID产生算法,一个int64_t字段就可以胜任,不像现在主流128bit的GUID算法,即使无法保证严格的id序列性,但是对于特定的业务,比如用做游戏服务器端的GUID产生会很方便。另外,在多线程的环境下,序列号使用atomic可以在代码实现上有效减少锁的密度。
参考资料:https://github.com/twitter/snowflake
(全文结束)
转载文章请注明出处:漫漫路 - lanindex.com
lock free 的id生成方式,不知道笔者有没有好的思路
而且我理解,nextId这个方法能够很快的执行完,锁的粒度很小,所以产生锁竞争的可能性就被降低了。另外一方面
如果没有锁竞争,lock和unlock操作是开销很小的操作,基本无性能影响
lock free的id生成方式我没有在生成环境中应用,只是一个设想:
在12bit序列号这里做文章,将其弄成Atomic,然后多线程测试在你的机器环境下1ms是否能跑完4095次id生成(12bit);
根据跑的次数多少自行调节原始12bit序列号的占位。
ok,3ks,是个不错的思路
内部维护的时间戳同样需要同步,所以一个AtomicLong并不能保证线程安全,官方的scala版本里同样是在整个取id的方法上加上了synchronized
我在[2016年7月20日 at 下午5:52]这个回复里解释了这个问题:
如果核少线程少,1毫秒用不完自增的序列ID就不用关心时间戳的锁;如果核多线程多,如你所说,内部维护的时间戳需要同步(因为若在同一毫秒,自增ID跑了一圈回到起点会重复)。
至于gettimeofday,linux线程安全的,无需担心。
如果要是中间的机器位超过了1024怎么办
可以自行调整时间戳、机器位、序列号所占的bit位大小。
刚用java写了一个并发1024个线程同时生成id的测试程序,然而并没有重复
用java写成单例模式就不会有重复的问题
机器ID怎么获取比较好呢,不依赖别的,又能达到分布式。
不依赖mysql的话,可以自己实现一个分配进程,根据请求过来的服务名:IP:PORT这三者关系hash出一个机器ID,手动解决一下碰撞,这种方式需要注意的是数据落地(万一进程挂了)和数据备份(万一进程所在的机器挂了);
如果连分配进程都不想实现,要满足这样的需求:A、B两台机器在毫无交流的情况下,根据特定的算法得到不一样的机器ID。好像目前没有合适的算法可以做到(例如有1000台机器,在互相不感知的情况下如何保证所有机器ID不一致);
还有一种实现和业务的耦合度会比较高,每次进程启动时向所有进程广播自己的机器ID(任意指定一个),所有其他进程回复自己的机器ID,若发现没有相同的就用开始指定的,若发现有相同就找一个和其他所有机器都不同的,这里需要解决的问题是进程同时启动的问题,缺点是增加了算法与具体业务的耦合性。
有几个问题不明白特此请教下,一:既然说了线程id的低10位会重复为何你还用set_workid(getpid()),二:这样的认为对不对,对于多进程情况下访问这个get_curr_ms()应该不会重复,二对于多线程下访问atomic_incr(int id) 这个不会重复,所以我认为只要传入10位不通的workid,应该就可以满足分布式唯一id生成了,请赐教
原算法的工作机器id是进程级的,线程id这个概念引入只是为了解决多线程环境下产生唯一ID的一种想法(实际线程id不是必须的,最初设计里面也没有);
第二个,你的理解差不多是这样的,多进程保证每个进程拥有不同的workid,然后每个进程包含的线程通过原子序列号自增来避免产生重复的结果。
默认情况下41bit的时间戳可以支持该算法使用到2082年,这是相对twepoch = 1288834974657L?使用该时间我算出来是2080年
不是相对twepoch = 1288834974657L,你的这个时间是2010年,41bit最多支持69.7年,所以是2080年。
可能是我基础太差了吧,不大看得懂。有几个问题向楼主请教:
1、既然是64位,为何第一位不使用呢?
2、怎么生成41位的时间戳?
3、工作机器id如果使用MAC地址的话,怎么转成10bit啊?
4、怎么生成12bit的序列号啊?
哎,怎么感觉啥都不懂,心好累
1、第一位不使用主要原因是为了保持产生uid的自增特点;
2、时间戳的问题:41位只是预留位(主要目的是约定使用年限),不用的位数填0就好了;
比如数字17,我们需要用14bit表示,就是00 0000 0001 0001
3、需要使用一个额外的工作机器id分配器,用来匹配id-MAC的唯一映射,文中“工作id”这块利用mysql的解决方案应该可以满足你的要求;
4、序列号不需要全局维护,使用atomic(int)从0自增。当序列号超过了12bit地址大小,序列号在这一毫秒用完了(一般用不完),waitNextMs()归0重置就可以了。
最高位bit标记为不可用 是为什么?
主要原因是为了保持产生uid的自增特性,最高位若用了,int64_t会表示为负数。
那最高位就是0 了
并发大会重复
嗯,是的。算法的本身从设计上并没有避免同一服务器上多线程并发数据重复的问题
(除非增加类似工作机器id的线程id数据,每个线程在自己的id段生成),这只是一种思路。
我使用时,在时间戳生成与比较代码处加了锁:D
atomic不是可以解决多线程的id重复问题么?
不太清楚你的atomic用在序列号,还是什么其他地方。
有这样一种简单实现,利用atomic的序列号可以完全避免用锁,不会产生重复id,剔除了时间戳比较,大体思路如下:
每次将序列号atomic++后存储到局部变量seq,若发现seq大于等于序列号最大值(根据分配序列号所占bit算出),那么等待下一毫秒。
但是这个实现有一个隐患是:因为缺少时间戳的比较,在同一毫秒内若线程A刚好把序列号用完处于waitNextMs状态,线程B刚好拿到atomic++后的1,同一毫秒循环回来又是同一个序列号….
其实把序列号设置的偏大点可以间接避免这个问题,比如设置超过1000,我有一个测试在E5-2640 2.50GHz单线程上,1毫秒大约可以产出120个uid。
这里最终极目标是改写成lock-free,且无隐患的方法,欢迎交流:D
T(1llu << 41)毫秒供你使用分配,年份 = T / (3600 * 24 * 365 * 1000) = 69.7年。
怎么算出来的. 我算了. 不止这些
就是2的41次方=2199023255552毫秒,然后一年的毫秒3600 * 24 * 365 * 1000 = 31536000000,前者除以后者约等于69.7。
这个是不是应从1970年算起啊,1970+69=2039,也就是说只能支持到2039年
代码实现上可以自己设置起始时间戳(比真实时间小的固定值)startStamp,然后使用generateStamp() – startStamp得到偏移时间进行时间位的填充。
这样就可以从自己设置的startStamp时间算起,而不是1970年。
一年的毫秒数 365 * 24 * 60 * 60 * 1000 = 1471228928 吧,怎么会是 31536000000 呢?
int32_t time = 365 * 24 * 60 * 60 * 1000; //这是错误的,365 * 24 * 60 * 60 * 1000默认是int32运算,其次int32_t不够存储
int64_t time = 365 * 24 * 60 * 60 * 1000; //这是错误的,365 * 24 * 60 * 60 * 1000默认是int32运算
time == 1471228928
正确:
int64_t time = 365 * 24 * 60 * 60 * 1000LL;
time = 31536000000
丰富的经验和严谨的思路,赞
应该是2的41次方,再减1吧 :)
:D,实际上是需要减(但是不减也不影响程序正确运行)。
比如我只有3bit供使用(000,001,010,011,100,101,110,111),
那么可以利用2的3次方个数(0-7,共8个数),若假设0就是代表第1毫秒,实际上可以对应第1毫秒到第8毫秒。
若约定从第0毫秒开始计算(即000代表第0毫秒),我们那么总数就是2的3次方,再减1,实际上可以对应第0毫秒到第7毫秒。
因为时间戳是41bit的长度,其中有一个bit是不使用的,因此有40个bit来表示时间戳,40个bit能够产生的最大组合个数是2的40次方个,也就是1024的4次方个,也就是1T个,每个组合可以表示一个数字,以毫秒为单位每年有3600 * 24 * 365 * 1000个毫秒,表示一个毫秒需要一个数字