设计目的
一、设计该排行服务器解决单点,让排行系统支持平行扩缩容。
二、做到秒级的排行刷新。
三、支持单榜万级数量,逻辑上易扩展。
主循环整体流程图
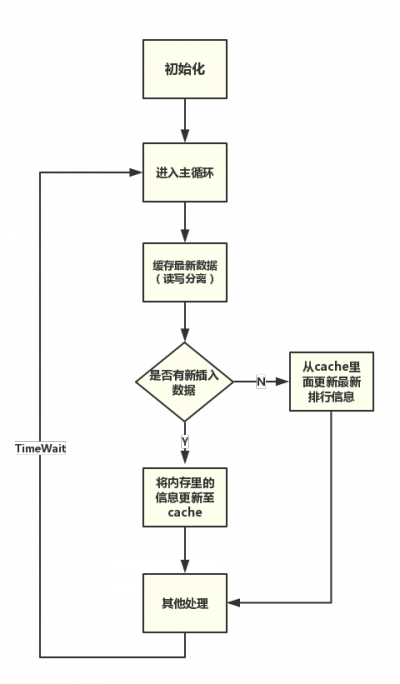
流程图的一些细节
1、根据排行类型进行Hash来选择目标节点机器,可考虑一致性Hash;
2、排行处理进程为多线程,一个主循环线程(逻辑如上图),N个消息处理线程(处理更新排行、拉取排行逻辑);
3、核心排行数据结构为std::multimap,积分作为key;在上图步骤<缓存最新数据>中将multimap数据按顺序落入vector作为拉取排行的备份数据结构,技巧是准备二个vector进行读写分离,减少锁的使用;
4、支持多点的核心逻辑在步骤<是否有新插入数据>,若有新插入数据,证明他是这类排行的Master,我们要将新数据存入至cache;若没有新数据插入,那么证明他是这类排行的Slave,我们需要从cache里面更新其Master存储进的数据;
若有额外需求
例如我们需要做一个“千万级”的排行榜。
拿最少1000W的数据举例,以一个int64的score作为key,int64的uid作为value,最后落入vector大约占用160M的内容,读写分离的数据结构不再适用。
衍生出 – 读写分离的框架结构:
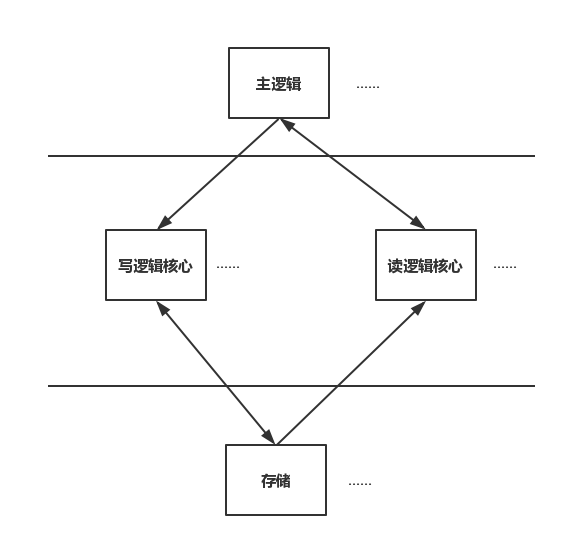
1、写逻辑与读逻辑是线程级的,可以将其混合在一个进程中,可以分离到独立的进程中,甚至分离不同机器上的进程中(图示中的方法);
2、写逻辑维护增量数据,读逻辑维护全量数据,均支持动态增减机器;
3、存储是负载比较高的点,需要考虑合适的高性能,高可用存储组件;
4、核心数据结构还是std::multimap,但是会根据积分来分段,例如1-10000;10001-20000……这种;
一些问题
一、关于核心数据结构选取,为什么不选择Skip-List(跳表)、以及传统的uid-score形式(本身无序的存储)?
先说下传统的uid-score形式,他的好处是在写逻辑简单,每次更新的内容少,不会在更新时产生数据冲突;坏处是,在读逻辑很重,需要想办法通知到读端哪些uid进行了更新,否则就得想办法全量更新;
再说下跳表,跳表是一个典型的空间时间互换的数据结构,跳表的高度一定程度上决定了它删除,查找,插入操作的时间复杂度。所以它的占用内存是大于std::multimap的,根据高度算法的合理性,大于的比例在20%~30%附近浮动。即使这样,在删除,查找,插入的耗时上也没有什么明显优势;
二、若进程挂掉,如何快速回复数据?
可以利用共享内存来做到快速回复数据;
三、若机器A宕机,那么已经更新至排行进程的数据,但是未同步到cache这部分数据会丢失。
这里设计到数据一致性问题(本文均是围绕最终一致性展开),为了解决这个问题可以在耦合性上做一些牺牲。拉取接口附带玩家最新分数的参数,更新接口附带玩家最近二次最高分数(可以理解为冗余的数据)。
(全文结束)
转载文章请注明出处:漫漫路 - lanindex.com